React Fiber详细解析
本文深入解析了 React Fiber 的核心实现原理和工作机制。文章首先介绍了 Fiber 产生的背景,解释了传统 React 更新机制存在的性能问题。随后详细阐述了 Fiber 的设计思路,包括 Fiber Node 的结构、任务调度机制、优先级计算、双缓存树的实现等核心概念。同时介绍了 Fiber 如何通过时间分片和可中断的调和过程来提升应用性能,以及如何通过 requestIdleCallback 和 requestAnimationFrame 来实现与浏览器的调度协作。通过本文,读者可以全面理解 React Fiber 架构的设计思想和实现细节。
React Fiber是什么?官方的解释是 “React Fiber是对核心算法的一次重新实现”。
使用 React 框架的开发者都知道,React 是靠数据驱动视图改变的一种框架,它的核心驱动方法就是用其提供的 setState 方法设置 state 中的数据从而驱动存放在内存中的虚拟 DOM 树的更新。
更新方法就是通过 React 的 Diff 算法比较旧虚拟 DOM 树和新虚拟 DOM 树之间的 Change ,然后批处理这些改变。
在 Fiber 诞生之前,React 处理一次 setState()(首次渲染)时会有两个阶段:
- 调度阶段(Reconciler):这个阶段React用新数据生成新的 Virtual DOM,遍历 Virtual DOM,然后通过 Diff 算法,快速找出需要更新的元素,放到更新队列中去。
- 渲染阶段(Renderer):这个阶段 React 根据所在的渲染环境,遍历更新队列,将对应元素更新。在浏览器中,就是更新对应的 DOM 元素。
表面上看,这种设计也是挺合理的,因为更新过程不会有任何 I/O 操作,完全是 CPU 计算,所以无需异步操作,执行到结束即可。
这个策略像函数调用栈一样,会深度优先遍历所有的 Virtual DOM 节点,进行 Diff 。它一定要等整棵 Virtual DOM 计算完成之后,才将任务出栈释放主线程。对于复杂组件,需要大量的 diff 计算,会严重影响到页面的交互性。
举个例子:
假设更新一个组件需要 1ms,如果有200个组件要更新,那就需要 200ms,在这200ms的更新过程中,浏览器唯一的主线程都在专心运行更新操作,无暇去做任何其他的事情。想象一下,在这 200ms 内,用户往一个 input 元素中输入点什么,敲击键盘也不会获得响应,因为渲染输入按键结果也是浏览器主线程的工作,但是浏览器主线程被 React 占用,抽不出空,最后的结果就是用户敲了按键看不到反应,等 React 更新过程结束之后,那些按键会一下出现在 input 元素里,这就是所谓的界面卡顿。
React Fiber,就是为了解决渲染复杂组件时严重影响用户和浏览器交互的问题。
Fiber产生的原因?
为了解决这个问题,react推出了Fiber,它能够将渲染工作分割成块并将其分散到多个帧中。同时加入了在新更新进入时暂停,中止或重复工作的能力和为不同类型的更新分配优先级的能力。
至于上面提到的为什么会影响到用户体验,这里需要简单介绍一下浏览器的工作模式:
因为浏览器的页面是一帧一帧绘制出来的,当每秒绘制的帧数(FPS)达到 60 时,页面是流畅的,小于这个值时,用户会感觉到卡顿,转换成时间就是16ms内如果当前帧内执行的任务没有完成,就会造成卡顿。
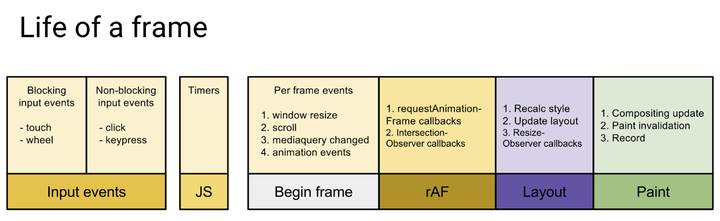
一帧中执行的工作主要以下图所示的任务执行顺序单线程依次执行。
如果其中一项任务执行的过久,导致总时长超过了16ms,用户就会感觉到卡顿了
上面提到的调和阶段,就属于下图的js的执行阶段。如果调和时间过长导致了这一阶段执行时间过长,那么就有可能在用户有交互的时候,本来应该是渲染下一帧了,但是在当前一帧里还在执行 JS,就导致用户交互不能马上得到反馈,从而产生卡顿感。
Fiber的设计思路
React 为了解决这个问题,根据浏览器的每一帧执行的特性,构思出了 Fiber 来将一次任务拆解成单元,以划分时间片的方式,按照Fiber的自己的调度方法,根据任务单元优先级,分批处理或吊起任务,将一次更新分散在多次时间片中,另外, 在浏览器空闲的时候, 也可以继续去执行未完成的任务, 充分利用浏览器每一帧的工作特性。
它的实现的调用栈示意图如下所示,一次更新任务是分时间片执行的,直至完成某次更新。
这样 React 更新任务就只能在规定时间内占用浏览器线程了, 如果说在这个时候用户有和浏览器的页面交互,浏览器也是可以及时获取到交互内容。
Fiber具体都做了什么?
React 在 render 第一次渲染时,会通过 React.createElement 创建一颗 Element 树,可以称之为 Virtual DOM Tree. 同时也会基于 Virtual DOM Tree 构建一个“结构相同” Fiber Tree。
Virtual DOM Tree 虚拟 DOM 树 虚拟 DOM 树的存在就是为了解决 js 直接操作真实 DOM 而引起的计算机计算能力的浪费。 因为通过 js 直接修改 DOM ,会引起整颗 DOM 树计算和改变,而虚拟 DOM 树的存在可以让真实 DOM 只改变必要改变的部分。
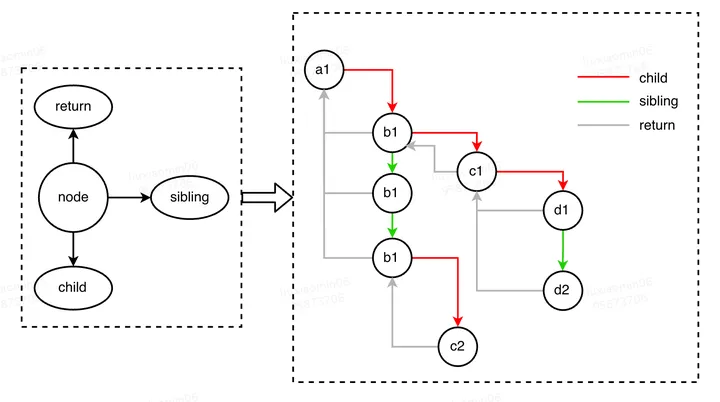
1、Fiber的调度单元: Fiber Node
Fiber Node,是 Fiber Tree 的基本构成单元,也可以类比成 Virtual DOM Tree 的一个节点(实际比它的节点多了很多上下文信息),也是 Fiber 中的一个工作单元。一个 Fiber Node 包含了如下内容
{
...
// 跟当前Fiber相关本地状态(比如浏览器环境就是DOM节点)
stateNode: any,
// 单链表树结构
return: Fiber | null,// 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回
child: Fiber | null,// 指向自己的第一个子节点
sibling: Fiber | null, // 指向自己的兄弟结构,兄弟节点的return指向同一个父节点
// 更新相关
pendingProps: any, // 新的变动带来的新的props
memoizedProps: any, // 上一次渲染完成之后的props
updateQueue: UpdateQueue<any> | null, // 该Fiber对应的组件产生的Update会存放在这个队列里面
memoizedState: any, // 上一次渲染的时候的state
// Scheduler 相关
expirationTime: ExpirationTime, // 代表任务在未来的哪个时间点应该被完成,不包括他的子树产生的任务
// 快速确定子树中是否有不在等待的变化
childExpirationTime: ExpirationTime,
// 在Fiber树更新的过程中,每个Fiber都会有一个跟其对应的Fiber
// 我们称他为`current <==> workInProgress`
// 在渲染完成之后他们会交换位置
alternate: Fiber | null,
// Effect 相关的
effectTag: SideEffectTag, // 用来记录Side Effect
nextEffect: Fiber | null, // 单链表用来快速查找下一个side effect
firstEffect: Fiber | null, // 子树中第一个side effect
lastEffect: Fiber | null, // 子树中最后一个side effect
....
};其中有几个属性需要重点关注:return(父节点)、child(子节点)、sibling(兄弟节点)、stateNode(对应的 DOM 节点),expirationTime (到期时间)、Effect (变更)。
- return:向上链接整颗树
- child:向下链接整棵树
- sibling:横向链接整颗树
- stateNode:与 DOM 树相连
- expirationTime:计算节点更新的优先级
- Effect**:**记录节点的变更
通过节点上的 child(孩子)、return(父)和 sibling (兄弟)属性串联着其他节点,形成了一棵 Fiber Tree (类似Virtual DOM tree)
Fiber Tree 是由 Fiber Node 构成的,更像是一个单链表构成的树,便于向上/向下/向兄弟节点转换
简单总结一下:
组件是React 应用中的基础单元,应用以组件树形式组织,渲染组件;
Fiber 调和的基础单元则是 fiber(调和单元),应用与 Fiber Tree 形式组织,应用 Fiber 算法;
组件树和 fiber 树结构对应,一个组件实例有一个对应的 fiber 实例;
Fiber 负责整个应用层面的调和,fiber 实例负责对应组件的调和;
2、规定调度顺序:expirationTime 到期时间
每个 Fiber Node 都会有一个 ExpirationTime 到期时间来确定当前时间片下是否执行该节点的更新任务。
它是以任务什么时候该执行完为描述信息的,到期时间越短,则代表优先级越高。
在 React 中,为防止某个 update 因为优先级的原因一直被打断而未能执行。React 会设置一个 ExpirationTime,当时间到了 ExpirationTime 的时候,如果某个 update 还未执行的话,React 将会强制执行该 update,这就是 ExpirationTime 的作用。
每一次 update 之前,Fiber都会根据当下的时间(通过 requestCurrentTime 获取到)和 更新的触发条件为每个入更新队列的 Fiber Node 计算当下的到期时间。
到期时间的计算有两种方式, 一种是对交互引起的更新做计算 computeInteractiveExpiration , 另一种对普通更新做计算 computeAsyncExpiration
function computeExpirationForFiber(currentTime: ExpirationTime, fiber: Fiber) {
let expirationTime;
// ......
if (fiber.mode & ConcurrentMode) {
if (isBatchingInteractiveUpdates) {
// 交互引起的更新
expirationTime = computeInteractiveExpiration(currentTime);
} else {
// 普通异步更新
expirationTime = computeAsyncExpiration(currentTime);
}
}
// ......
}
// ......
return expirationTime;
}computeInteractiveExpiration
export const HIGH_PRIORITY_EXPIRATION = __DEV__ ? 500 : 150;
export const HIGH_PRIORITY_BATCH_SIZE = 100;
export function computeInteractiveExpiration(currentTime: ExpirationTime) {
return computeExpirationBucket(
currentTime,
HIGH_PRIORITY_EXPIRATION,//150
HIGH_PRIORITY_BATCH_SIZE,//100
);
}computeAsyncExpiration
export const LOW_PRIORITY_EXPIRATION = 5000;
export const LOW_PRIORITY_BATCH_SIZE = 250;
export function computeAsyncExpiration(
currentTime: ExpirationTime,
): ExpirationTime {
return computeExpirationBucket(
currentTime,
LOW_PRIORITY_EXPIRATION,//5000
LOW_PRIORITY_BATCH_SIZE,//250
);
}查看上面两种方法,我们发现其实他们调用的是同一个方法:computeExpirationBucket,只是传入的参数不一样,而且传入的是常量。computeInteractiveExpiration 传入的是150、100,computeAsyncExpiration 传入的是5000、250。说明前者的优先级更高。那么我把前者称为高优先级更新(交互引起),后者称为低优先级更新(其他更新)。
computeExpirationBucket
const UNIT_SIZE = 10;
const MAGIC_NUMBER_OFFSET = 2;
function ceiling(num: number, precision: number): number {
return (((num / precision) | 0) + 1) * precision;
}
function computeExpirationBucket(
currentTime,
expirationInMs,
bucketSizeMs,
): ExpirationTime {
return (
MAGIC_NUMBER_OFFSET +
ceiling(
currentTime - MAGIC_NUMBER_OFFSET + expirationInMs / UNIT_SIZE,
bucketSizeMs / UNIT_SIZE,
)
);
}最终的公式是:((((currentTime - 2 + 5000 / 10) / 25) | 0) + 1) * 25
其中只有只有 currentTime 是变量, currentTime 是通过浏览提供的API(requestCurrentTime)获取的当前时间。
简单来说,以低优先级来说, 最终结果是以25为单位向上增加的,比如说我们输入102 - 126之间,最终得到的结果都是625,但是到了127得到的结果就是650了,这就是除以25取整的效果。 即,低优先级更新的 expirationTime 间隔是 25ms,抹平了 25ms 内计算过期时间的误差,React 让两个相近(25ms内)的得到 update 相同的 expirationTime ,目的就是让这两个 update 自动合并成一个 Update ,从而达到批量更新。
高优先级是10ms的误差.
也就是说 expirationTime 的计算是将一个时间段内的所有任务都统一成一个 expirationTime ,并且允许一定误差的存在。
随着时间的流逝,一个更新的优先级会越来越高,这样就可以避免 starvation 问题(即低优先级的工作一直被高优先级的工作打断,而无法完成)。
另外,之前存在过一个 PriorityLevel 的优先级评估变量,但在 16.x 中使用的是 expirationTime 来评估,但为了兼容仍然会考虑 PriorityLevel 来计算 expirationTime。
3、workInProgress Tree : 保存更新进度快照
workInProgress Tree 保存当先更新中的进度快照,用于下一个时间片的断点恢复, 跟 Fiber Tree 的构成几乎一样, 在一次更新的开始时跟 Fiber Tree 是一样的.
4、Fiber Tree 和 WorkInProgress tree的关系
在首次渲染的过程中,React 通过 react-dom 中提供的方法创建组件和与组件相应的 Fiber (Tree) ,此后就不会再生成新树,运行时永远维护这一棵树,调度和更新的计算完成后 Fiber Tree 会根据 effect 去实现更新。
而 workInProgress Tree 在每一次刷新工作栈( prepareFreshStack )时候都会重新根据当前的 fiber tree 构建一次。
这两棵树构成了双缓冲树, 以 fiber tree 为主,workInProgress tree 为辅。
双缓冲具体指的是 workInProgress tree 构造完毕,得到的就是新的 fiber tree ,每个 fiber 上都有个 alternate 属性,也指向一个 fiber ,创建 workInProgress 节点时优先取 alternate ,没有的话就创建一个。
fiber 与 workInProgress 互相持有引用,把 current 指针指向 workInProgress tree ,丢掉旧的 fiber tree 。旧 fiber 就作为新 fiber 更新的预留空间,达到复用 fiber 实例的目的。
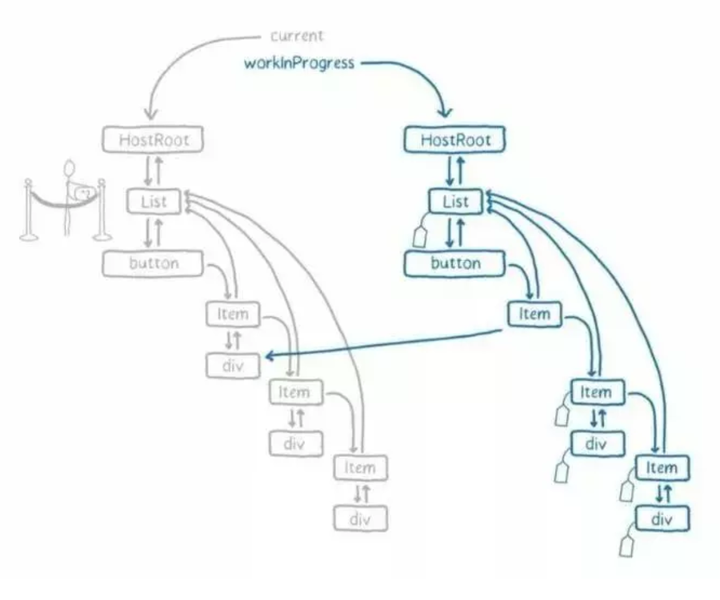
一次更新的操作都是在 workInProgress Tree 上完成的,当更新完成后再用 workInProgress Tree 替换掉原有的 Fiber Tree ;
这样做的好处:
- 能够复用内部对象(fiber)
- 节省内存分配、GC 的时间开销
- 就算运行中有错误,也不会影响 View 上的数据
5、更新
怎么触发的更新
- this.setState();
- props 的改变(因为 props 改变也是由父组件的 setState 引起的, 其实也是第一种);
- this.forceUpdate();
触发更新后 Fiber 做了什么
首先, 当前是哪个组件触发的更新, React 是知道的( this 指向), 于是 React 会针对当前组件计算其相应的到期时间(上面mentioned计算方法), 并且基于这个到期时间, 创建一个更新 update , 将引起改变的 payload (比如说 state/props ), 作为此次更新的一个属性, 并插入当前组件对应的 Fiber Node 的更新队列(它是一个单向链表数据结构。只要有 setState 或者其他方式触发了更新,就会在 fiber 上的 updateQueue 里插入一个 update,这样在更新的时候就可以合并一起更新。)中, 之后开始调度任务。
整个调度的过程是计算并重新构建 workInProgress Tree 的过程,在 workInProgress Tree 和原有 Fiber Tree 对比的时候记录下 Diff,标记对应的 Effect, 完成之后会生成一个 Effect List,这个 Effect List 就是最终 Commit 阶段用来处理副作用的阶段, 如果在这个过程中有了交互事件等高优先级的任务进来,那么 fiber 会终止当前任务, 执行更紧急的任务, 但为了避免 “饥饿现象”, 上一个吊起的任务的优先级会被相应的提升。
let workInProgress = current.alternate;
if (workInProgress === null) {
//...这里很有意思
workInProgress.alternate = current;
current.alternate = workInProgress;
} else {
// We already have an alternate.
// Reset the effect tag.
workInProgress.effectTag = NoEffect;
// The effect list is no longer valid.
workInProgress.nextEffect = null;
workInProgress.firstEffect = null;
workInProgress.lastEffect = null;
}6、effect
每一个 Fiber Node 都有与之相关的 effect , effect 是用于记录由于 state 和 props 改变引起的工作类型, 对于不同类型的 Fiber Node 有不同的改变类型,比如对 DOM 元素,工作包括添加,更新或删除元素。对于 class 组件,React 可能需要更新 ref 并调用 componentDidMount 和 componentDidUpdate 生命周期方法。
每个 Fiber Node 都有个 nextEffect 用来快速查找下一个改变 effect,他使得更新的修改能够快速遍历整颗树,跳过没有更改的 Fiber Node。
例如,我们的更新导致 c2 被插入到 DOM 中,d2 和 c1 被用于更改属性,而 b2 被用于触发生命周期方法。副作用列表会将它们链接在一起,以便 React 稍后可以跳过其他节点。
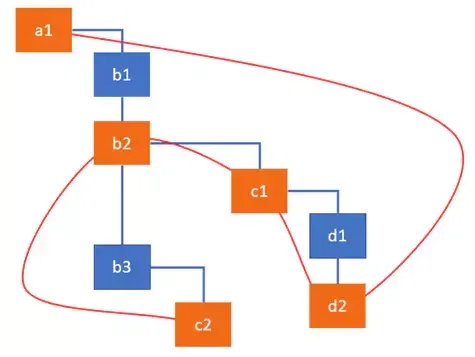
可以看到具有副作用的节点是如何链接在一起的。当遍历节点时,React 使用 Fiber Node 的 firstEffect 指针来确定列表的开始位置。所以上面的图表可以表示为这样的线性列表:

7、获取浏览器的控制权 --- requestIdleCallback 和 requestAnimationFrame
构建出 Effect List 就已经完成了一次更新的前半部分工作调和,在这个过程中,React 通过浏览器提供的 Api 来开始于暂停其中的调和任务。
requestIdleCallback(callback) 这是浏览器提供的 API ,他在 window 对象上,作为参数写给这个函数的回调函数,将会在浏览器空闲的时候执行。回调函数会有一个 deadline 参数,deadline.timeRemaining() 会告诉外界,当前时间片还有多少时间。利用这个 API ,结合Fiber拆分好的工作单元,在合适的时机来安排工作。

不过这个API只负责低优先的级的任务处理,而高优先级的(比如动画相关)则通过 requestAnimationFrame 来控制 。
如果浏览器支持这两个 API 就直接使用,如果不支持就要重新定义了,如果没有自行定义的https://juejin.im/post/5a2276d5518825619a027f57
8、调度器(Scheduler)
- 调和器主要作用就是在组件状态变更时,调用组件树各组件的 render 方法,渲染,卸载组件,而Fiber使得应用可以更好的协调不同任务的执行,调和器内关于高效协调的实现,我们可以称它为调度器(Scheduler)。 Fiber 中的调度器主要的关注点是:
- 合并多次更新:没有必要在组件的每一个状态变更时都立即触发更新任务,有些中间状态变更其实是对更新任务所耗费资源的浪费,就比如用户发现错误点击时快速操作导致组件某状态从 A 至 B 再至 C,这中间的 B 状态变更其实对于用户而言并没有意义,那么我们可以直接合并状态变更,直接从 A 至 C 只触发一次更新;
- 任务优先级:不同类型的更新有不同优先级,例如用户操作引起的交互动画可能需要有更好的体验,其优先级应该比完成数据更新高;
- 推拉式调度:基于推送的调度方式更多的需要开发者编码间接决定如何调度任务,而拉取式调度更方便 React 框架层直接进行全局自主调度;
调度的实现逻辑主要是
- 通过 fiber.return 属性,从当前 fiber 实例层层遍历至组件树根组件;
- 依次对每一个 fiber 实例进行到期时间判断,若大于传入的期望任务到期时间参数,则将其更新为传入的任务到期时间;
- 调用 requestWork 方法开始处理任务,并传入获取的组件树根组件 FiberRoot 对象和任务到期时间;
Fiber执行流程
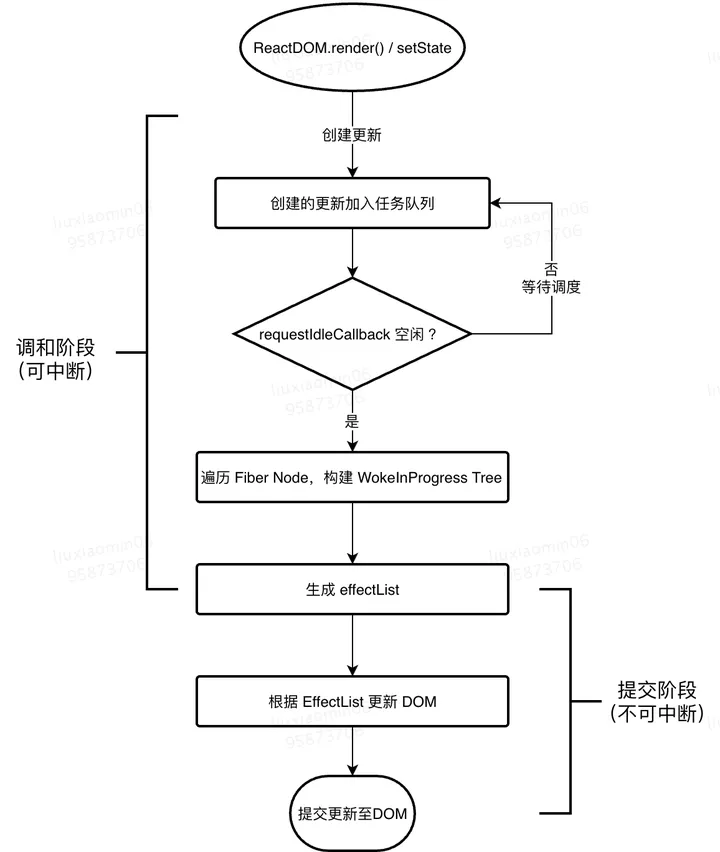
Fiber 总的来说可以分成两个部分,一个是调和过程(可中断),一个是提交过程(不可中断)。
在调和过程中以 fiber tree 为基础,把每个 fiber 作为一个工作单元,自顶向下逐节点构造 workInProgress tree(构建中的新 fiber tree )
具体过程如下:
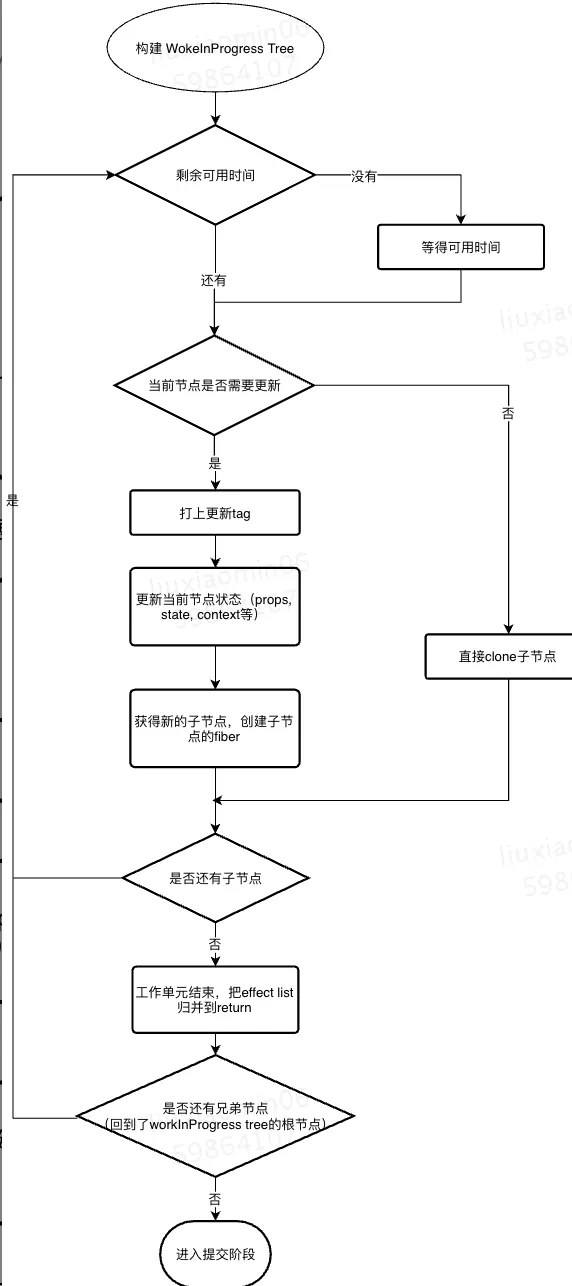
通过每个节点更新结束时向上归并effect list来收集任务结果,reconciliation 结束后,根节点的 effect list 里记录了包括 DOM change 在内的所有 side effect
所以,构建 workInProgress tree 的过程就是 diff 的过程,通过 requestIdleCallback 来调度执行一组任务,每完成一个任务后回来看看有没有插队的(更紧急的),每完成一组任务,把时间控制权交还给主线程,直到下一次 requestIdleCallback 回调再继续构建 workInProgress tree
而提交过程阶段是一口气直接做完(同步执行),不被控制中和止,这个阶段的实际工作量是比较大的,所以尽量不要在后3个生命周期函数里干重活儿
- 处理 effect list(包括3种处理:更新 DOM 树、调用组件生命周期函数以及更新 ref 等内部状态)
- 该阶段结束时,所有更新都 commit 到 DOM 树上了。
DEMO对比:
- 未使用Fiber的例子: https://claudiopro.github.io/react-fiber-vs-stack-demo/stack.html
- 使用Fiber的例子:https://claudiopro.github.io/react-fiber-vs-stack-demo/fiber.html
总结
其实我们在使用React 16以上的版本开发时, React自动会使用Fiber进行调度。 在我们通常开发的页面中并没有足够多的节点,能够让我们体会到fiber调度的优势,所以我们对Fiber的关注可能很少,不过一旦遇到了复杂的页面我们就能体会到Fiber调度的精妙之处。 另外学习Fiber的调度流程,也可以更深刻的理解浏览器的工作机制以及React开发中的数据流向,方便我们在开发中快速的定位问题。
注意啦:fiber 是解决性能问题的,而 hooks 是解决逻辑复用问题的
参考:
VPGAME科技头条:从React16生命周期到React fiber架构
[「译」如何以及为什么 React Fiber 使用链表遍历组件树](「译」如何以及为什么 React Fiber 使用链表遍历组件树 - 掘金 (juejin.cn))
[React16源码解析(三)-ExpirationTime](javascript - React16源码解析(三)-ExpirationTime - 个人文章 - SegmentFault 思否)
[「译」React Fiber 那些事: 深入解析新的协调算法](「译」React Fiber 那些事: 深入解析新的协调算法 - 掘金 (juejin.cn))